将视频转为文字—Python
type
Post
category
技术工具
tags
Python
slug
learning-python-video-to-text
summary
将视频里的语音转成文字,方便快速做学习笔记~。推荐两个提取视频文字的工具。
status
Published
date
Jun 4, 2021
icon
password
前言
用python实现将视频的声音对白转换成文字,可有以下两种方案:
- 提取视频字幕
往往视频作者都会在视频底部加上字幕,以提升观看体验。我们可以利用这点,通过python的图像库截取视频画面,再通过文字OCR识别图像上字幕,转写成文字。
- 视频→音频→文字
有的视频是没有字幕的,我们可以利用python的媒体库,将视频源文件转成音频格式,再对音频格式进行语音识别文字。
功能实现
1.整体思路
- 读取媒体文件
- 根据媒体文件类型统一转成WAV格式的音频
- 将音频分割成30秒以内的短音频(有利于提高调用成功率,并支持多线程以提高效率)
- 调用语音转文字服务,将音频转为文字,存入txt文本中
- 将多个文本按照顺序合并
2.借助的工具
- python
speech_recognition语音识别库;支持 google、ibm、bing等多家的语音转写开放接口,本文使用的 Google Web Speech API。

SpeechRecognition 自身附带了 Google Web Speech API 的默认 API 密钥,可直接使用它。其他几个 API 都需要申请密钥或用户名/密码组合进行身份验证。
这几个库中只有
recognition_sphinx 与CMU Sphinx 支持引擎脱机工作,其他六个都要连接互联网。pydub, 音频格式转换;
VideoFileClip, 视频格式转换;
3.项目代码实现
以下是主方法代码片段:
详情请访问Github源码 https://github.com/tangly1024/Video2Text
4.已知缺陷
- 需要科学上网,否则无法使用谷歌音频转写接口
- 文字分段突兀,由于音频被按照30秒强行切开的,而不是按照断句分割,所以最好手动校对结果。
- 没有标点符号。
调用演示
具体可以下载开源代码,在自己的电脑上运行,这里简单演示运行正确的过程 :
安装启动步骤
- 下载安装社区版本即可
- 安装 一路Next即可


安装截图
- 导入代码
导入截图,从Github下载代码导入
3.设置编译环境 venv
venv 是一个虚拟环境,设置虚拟环境后,此项目的所有依赖都会独立地被安装在当前虚拟环境下;有助于将本项目依赖与电脑上的全局环境隔离,确保系统环境干净。
点击File->Setting,如图:
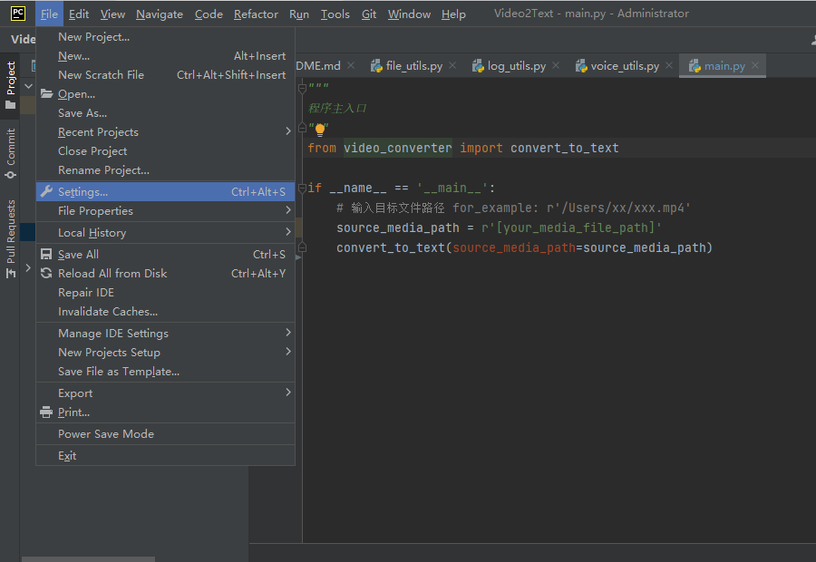
在Project Interpreter 中点击 Add Interpreter 并点击 Add Local Interpreter
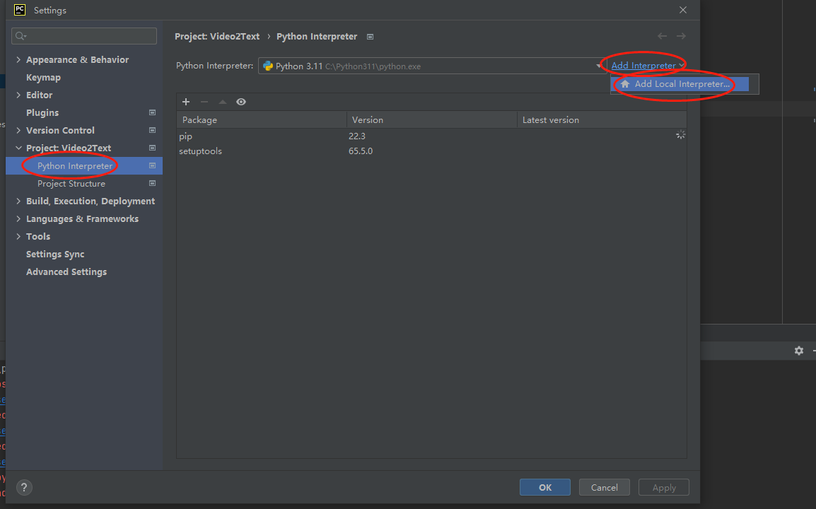
在弹出框中,Pycharm会自动在当前项目下创建一个venv虚拟的python环境,如图:
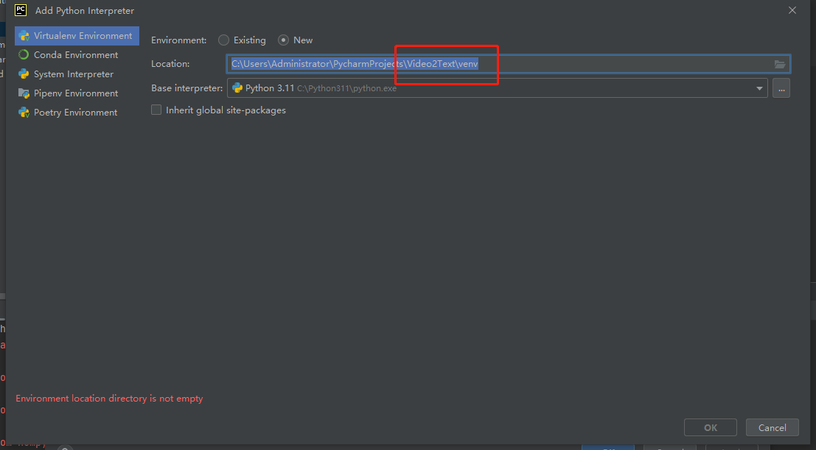
直接点击OK即可,我这里因为已经创建过了,所以OK按钮不能点击
点击下拉框,将当前环境设置为刚创建的虚拟环境,如图:
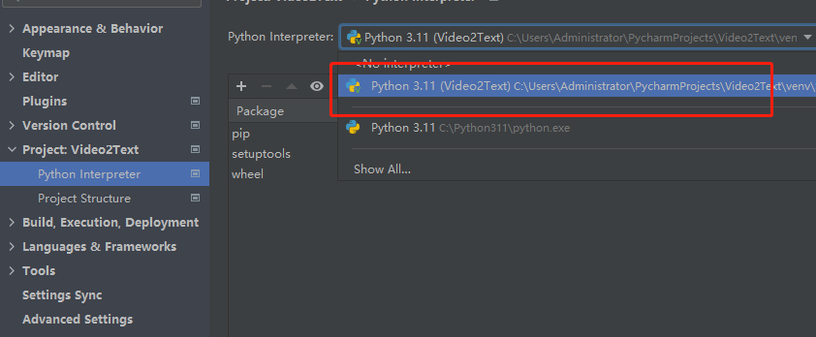
4.在虚拟环境中安装第三方依赖
上面切换环境后,重启一下Pycharm,不然会读取失败
在底部,terminal中 输入
安装过程截图:


转换效果
- 将源文件的mp4,mp3等文件统一转wav音频

- 将音频文件分割成多个

- 批量调用API转换文字

- 输出结果
如图:在output目录下会生成一个与你的原视频同名的音频文件和文本文件。而在/output/split目录下是被分割后的文件。
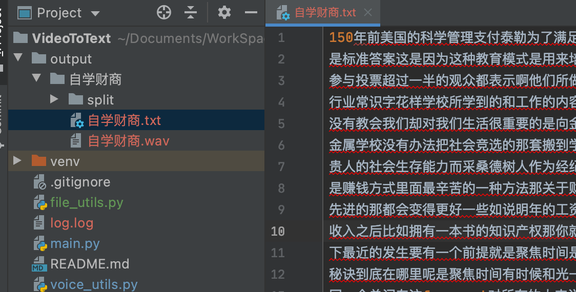
最后
这个python小程序的转换效果还有很大的优化空间,另外,网上有提供一些在线视频转文字的服务,使用体验都很不错:
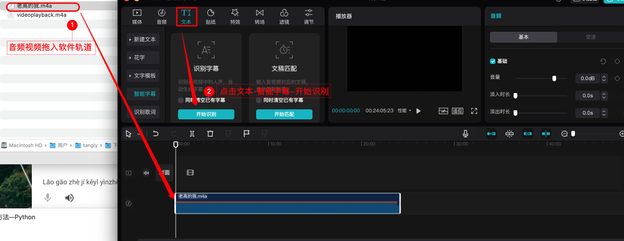
剪映专业版
这是一个视频剪辑的神器,步骤很简单,将素材拖入轨道,然后点击文本-智能字幕-开始识别即可。
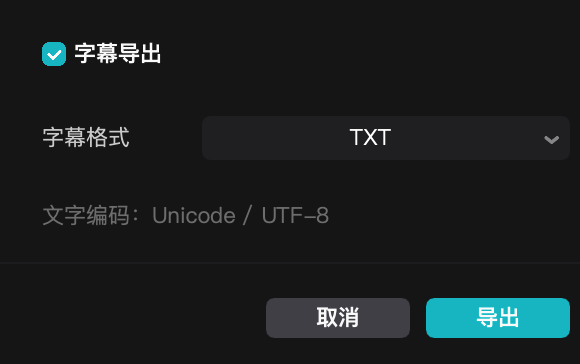
选择 文件 - 导出 - 然后仅勾选字幕导出即可。
微信小程序抖乐推小助手
微信轻抖小程序提取视频文案
创作猫App支持粘贴视频链接直接转文字

蜜蜂剪辑的在线视频转文字。


PDF365在线视频转写文字


作者:NotionNext
声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
Previous
Github 无法推送或拉取代码的解决
Next
Python入门(三)—— 文字转图片处理